
Rewiring the Matrix: Grass's Blueprint for AI's Data Democracy
This article explores the current challenges in AI data we face and how Grass, as a democratic data layer of AI, works to foster a more equitable and innovative AI landscape

Key Takeaways
Grass is a decentralized network aiming to democratize AI data access by leveraging crowdsourced bandwidth for web scraping.
With over 2 million nodes globally, Grass demonstrates its capability to scrape large datasets and real-time data access will be available in the LCR engine.
Grass is developing a Layer 2 data rollup on Solana and aims to scale 100 million nodes on its AI data layer.
The $GRASS token announcement and airdrop have generated both excitement and controversy in the community.
Premarkets and Gigabuds prices suggest an FDV of $400-$600 million for Grass, but it may fluctuate with notable listings and variation of market conditions.
While innovative, Grass faces significant challenges in network effects, data privacy, legal compliance, and maintaining user engagement.
Introduction
In the AI era, data is the new gold. AI models and algorithms process vast amounts of data to generate insights, make predictions, and solve complex problems. Unlike historical gold rushes, the digital treasure is generated by users but controlled by a handful of tech conglomerates. The concentration of data sources has created a digital divide, leading to data opacity and undervaluing contributors while hindering competition from AI startups and open-source projects.
This article explores the current challenges in AI data we face and how Grass, as a democratic data layer of AI, works to foster a more equitable and innovative AI landscape.

Data Utilization in AI
AI models utilize data as their foundation, learning and improving through the analysis of vast datasets. This process, known as machine learning, involves training models on labeled data, where each data point is paired with a corresponding output. By identifying patterns and relationships within data, models can make predictions or decisions on new, unseen data.

Both the quality and quantity of data significantly impact AI models’ accuracy and effectiveness. Biased or insufficient data can lead to unreliable outcomes, underscoring the importance of robust, accessible data provision for building reliable AI systems.
The AI Data Landscape
Currently, large tech conglomerates like Google, Microsoft, and Facebook are dominating the AI ecosystem. These companies have vast resources and built-in advantages to collect and process data for training AI models. While these giants have undeniably propelled AI development and adoption, their concentrated power—particularly over data—has fostered a digital divide. The imbalance severely restricts data access for smaller entities and impedes innovation across the sector. In fact, a select few tech conglomerates effectively control the majority of internet data, capitalizing on user-generated content while simultaneously erecting barriers to competitor access.
Lack of Data Transparency
The giants’ data monopoly has caused a number of concerns in the AI industry so far. For instance, the lack of transparency in AI training data sources is becoming worrying. According to the October 2023 transparency study by Stanford researchers, among general low transparency across AI system development, transparency about data is particularly poor. The opacity surrounding AI training data sources also raises concerns about bias and reliability, while the inability to verify data provenance opens the door to manipulation and misinformation.

Limited Data Access
Data accessibility is another emerging problem, where smaller companies and open-source projects are struggling with limited access to public web data for AI training. More and more large social platforms have begun to charge or raise fees for their API access. For example, X stopped supporting free access to their API in February 2023. Soon after, Reddit announced its intentions to charge fees for its API in April 2023, a feature which had been free since 2008. The exorbitant amount of data cost is becoming a significant barrier for smaller players to engage in AI development.

Inequitable Value Distribution
More significantly, the benefits of AI's growth are largely flowing to those who control the data, leaving the wider public – whose online activities generate the valuable data information – without a stake in the AI revolution. A stark example is Google’s recent $60 million deal with Reddit, which allows the search giant to train its AI models on user-generated content from millions of Reddit posts and comments. While Reddit benefits financially, the users whose posts and interactions form the backbone of the valuable dataset see no direct compensation. The current model doesn't provide a way for average internet users to benefit from the value of the data they generate through their online activities. A number of people still "simply view the Data Wars as infighting between factions of the Silicon Valley elite with no possible benefit to themselves". The lack of incentives and inequitable distribution will no doubt limit the participation of ordinary people in the AI revolution.
Traditional Solutions and Limitations
So, why don't we circumvent the giants and build open source datasets or just scrape directly from open websites? Indeed, some smart brains have already done that, but it seems to be utterly inadequate.
Open Source Datasets
There are some open source datasets available for AI researchers, such as WikiData and Open Data Initiative, aiming to promote data availability in the space. But these free and open-source knowledge bases face several challenges, including long-term sustainability and scalability. As many open-source datasets rely on grants, donations, or volunteer efforts, it can be inconsistent or insufficient for long-term maintenance. Meanwhile, along with the growth of datasets, the costs and technical challenges of hosting and distributing large volumes of data increase exponentially.
Web Scraping from Data Centers
Traditionally, web scraping from data centers is a cost efficient method to access large amounts of data. However, as more websites are trying to protect their data, web scraping from data centers can be easily blocked or circumvented. Websites can identify and block IP addresses associated with known data centers. Additionally, data center traffic often shows patterns typical of automated scraping (high volume, consistent timing) and lack the variability and "noise" associated with real user behavior, thus making them more identifiable and vulnerable to being targeted.

In response to these challenges, innovative solutions are emerging to democratize access to web data and remodel the AI data landscape. One such pioneering project is Grass, which aims to address the inadequacy of traditional data accessibility solutions by leveraging the power of decentralized networks.
Introducing Grass: A Decentralized Data Accessibility Layer
Grass is a decentralized network that allows anyone with an internet connection to install a node on their device and contribute their unused bandwidth for web scraping purposes. It aims to empower open source AI by giving smaller players access to verifiable training data and, at the same time, compensate users for a practice that has been happening for 20-30 years without proper remuneration.

To put simply, Grass works by harnessing the power of the crowd to create a decentralized web scraping network. Imagine millions of everyday internet users transforming their devices into tiny, efficient data collectors. That's the core innovation of Grass. Users install a node on their internet-connected devices, which then utilizes their excess bandwidth to scrape public web data. These mini data miners create a vast, distributed network that's incredibly difficult for websites to block or detect.
Notably, Grass users can get point or token rewards for renting their idle bandwidth. On the data consumption side, a wide range of AI startups, developers and researchers can easily access such crowdsourced data in a cost-efficient way.
In essence, Grass leverages tokenomics as an incentive mechanism to turn the internet into a collectively-owned data mine, where everyone can participate in and benefit from the AI gold rush.
Progress and Milestones
Grass Contributors
Wynd Labs, previously known as Wynd Network, is a core contributor to Grass and operates a decentralized web proxy network specializing in AI data solutions. Co-founder and CEO Andrej Radonjic holds a Master's in Mathematics and Statistics from York University and has invested in AI startups like rug.ai. CTO Chris Nguyen is a YC alumnus and he brings experience from Neurox, a GPU resource management company. In addition, several core contributors, such as 0xcontentooo and BeepboopMichael, are also active on social media.
Product Development
Now, let's examine Grass's current progress and market position. Grass beta was initially launched in June 2023. Within months of its launch, Grass secured a significant $3.5 million seed round led by notable capitals such as Polychain Capital and Tribe Capital, bringing its total funding to $4.5 million. The financial backing accelerated its growth and adoption quickly. By mid-2024, Grass had already built an impressive network of over 2 million nodes globally, making it one of the largest crypto and DePIN projects in terms of real users.
A major milestone was reached when the network demonstrated its capability by scraping the entirety of Reddit's 2024 data in less than a week, which showed the network's ability to quickly gather large amounts of data from a major web platform. Recently, Grass made a significant contribution to open data by releasing over 600 million Reddit posts and comments on Hugging Face.

At the moment, Grass can scrape over 40 TB of public web data daily, primarily driven by multimodal AI needs. Remarkably, it represents less than 1% of the network's full capacity, and doesn't even include data from the early Live Context Retrieval (LCR) alpha tests.

According to Andrej Radonjic’s recent post, Grass's value to the AI industry extends far beyond providing large datasets for model training. The true game-changer will be its Live Context Retrieval (LCR) engine, which will enable any AI model to access and leverage real-time data from across the public web, significantly expanding the potential applications and capabilities of AI systems.
As Grass continues to expand, it is setting its sights on even more ambitious goals, including:
Expanding to multiple devices, ranging from desktops to IOS and Android devices
Scaling to 20-25 million nodes, which could scrape enough data to train GPT-3.5 from scratch weekly
The ultimate goal of Grass is to scale to 100 million nodes, enabling an internet-scale web crawl, and position itself as the data layer of AI. Beyond data collection, Grass is also working on the development of a Layer 2 data rollup solution, which aims to process and structure the collected data for AI training purposes.
GigaBuds
GigaBuds is a collection of 10,000 unique NFTs associated with the Grass community. It was launched on Solana with a focus on community engagement and utility for its holders. Each NFT in this collection is designed as a 2D profile picture (PFP) with a focus on individuality and rarity.

While specific utilities for GigaBuds were not fully detailed in the provided information, there's an expectation of benefits tied to the broader Grass ecosystem, including governance rights, access to exclusive features, or $GRASS token airdrop.
Why Another Layer 2?
The Grass Layer 2 data rollup solution represents a significant advancement in AI data processing and management. Basically, Grass will operate as a Layer 2 solution on Solana, leveraging Solana's high throughput for transaction settlement. The Layer 2 architecture consists of several key components, including:
Grass Data Ledger: it acts as a repository where all data collected by the network is stored. Each dataset includes metadata like session keys, URLs, timestamps, and IP addresses, ensuring traceability and authenticity of data.
ZK Processor: It utilizes Zero-Knowledge proofs to validate data without revealing the data itself. The ZK tech ensures privacy and security, with proofs stored on Solana's Layer 1 for settlement.
Nodes: Users with the Grass extension act as nodes, scraping web data. The decentralized approach to data collection leverages residential internet users' bandwidth, enhancing data diversity and reducing the risk of IP bans.
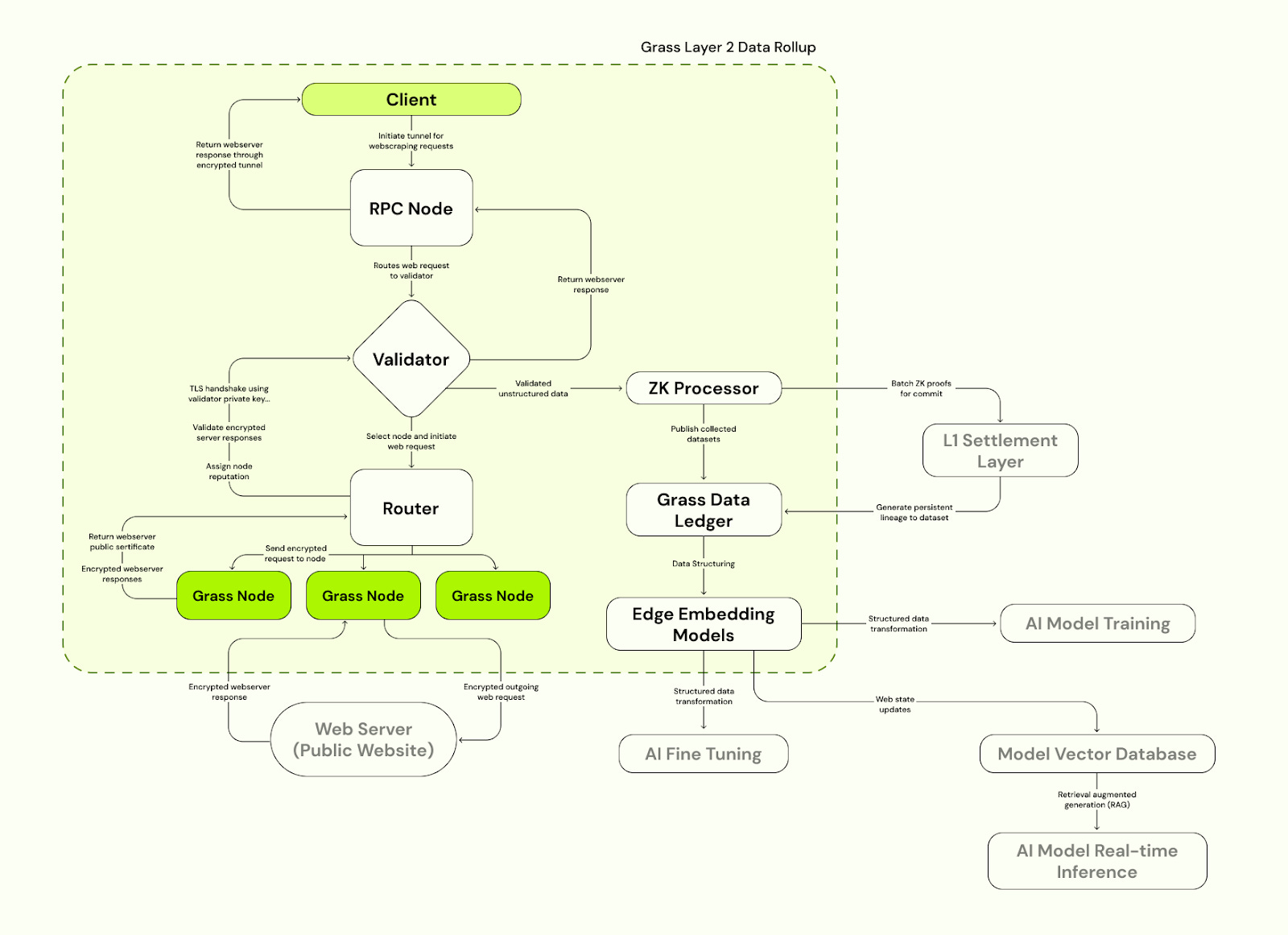
The Layer 2 network is designed for data flow and processing, e.g., data collection, verification and storage, in the Grass ecosystem. Grass claims to process up to 1 million transactions per second, which is facilitated by Solana's underlying infrastructure. The use of Layer 2 for data rollups reduces the load on Solana mainnet and offers a variety of customizations, allowing for more flexible and efficient data processing.
In a word, the Grass Layer 2 solution not only aims to solve scalability issues in blockchains but also introduces a novel approach to data management for AI, emphasizing privacy, security, and efficiency through decentralized data collection and processing.
Token Economics and Airdrop
The Grass closed alpha campaign had just ended and the first Grass airdrop was recently announced. Eligibility for the airdrop can be verified at grassfoundation.io/eligibility. In short, $GRASS total supply will be 1 billion tokens, with 10% set aside for the first airdrop. The token launch date and detailed tokenomics are currently undisclosed (coming soon!). However, based on code analysis by PhatmoSolana, a Grass community member, Grass will probably have a staking and delegation function in the future.
The First Grass Airdrop Breakdown goes as follows:
Closed Alpha: 1.5%
Epochs 1-7: 7%
Bonus Epoch: 0.5%
To Be Announced: 1%
The allocations shown on the airdrop checker were not the final amounts, as Grass Foundation clarified that there were still pending allocations from a bonus epoch and other unannounced distributions.
Despite the anticipation, the airdrop faced considerable community backlash, primarily due to:
Low Token Rewards: Many users felt that the token allocations they received were too small, especially considering the effort and time invested. Some users expressed disappointment over receiving what they deemed as insignificant amounts, comparing their rewards unfavorably to the cost of a "Big Mac."
Value Dilution Concerns: With over 2 million active users, the airdrop's rewards were significantly diluted, leading to dissatisfaction over the perceived value of participation.

While some community members expressed concerns about individual allocation sizes, it's important to consider the broader implications of the airdrop distribution:
Wide Token Distribution: By including over 2 million users in the airdrop, Grass has achieved one of the widest token distributions in recent crypto history. The broad reach aligns with the project's decentralized ethos and helps create a diverse, engaged community from the outset.
Fair Launch Principles: By allocating a substantial portion of tokens to early users and contributors, Grass demonstrates a commitment to rewarding those who helped build the network from the ground up.
Whale Allocation Cap: Though the official Grass airdrop criteria are not announced, it seems that whale airdrop allocations are capped and the airdrop rules even favor lower-tier users, according to a community dashboard.

Market and Valuation Analysis
Despite the Grass token not being officially live, $GRASS has been trading in pre-markets like Whales Market and Aevo, at approximately $0.45 and $0.65 per token respectively, implying a fully diluted valuation (FDV) of $450-$650 million.
To estimate a fair valuation for Grass, let's examine the market capitalizations and valuations of its competitors and peers in the Decentralized Physical Infrastructure Networks (DePIN) and Crypto AI sectors.
Considering its 1 billion tokens with 10% for airdrop, it's reasonable to assume the circulating tokens on Token Genesis Event (TGE) would be 10-20% (including market making and liquidity tokens). If we look at recent projects with notable CEX listings, such as io.net and Atheir, the Grass FDV could be around $1 billion. Alternatively, if Grass launches without a major CEX listing, its FDV is likely to be around $500 million. And of course, the above predictions are for reference only and may vary with the macro fluctuation and market sentiment shift.
(PS: Grass has announced a new round of financing led by Hack VC. While the exact amount of the funding has not been disclosed, insiders indicated that this latest round has brought Grass Network's valuation to nearly one billion dollars.)

Since GigaBuds has a floor price of 2.5 $SOL (~$350 at current $SOL price) on Magic Eden, it may be a good reference for the potential valuation of Grass. At present, communities are anticipating 1% $GRASS allocation for GigaBuds holders, indicating that 1 GigaBuds is eligible for 1000 $GRASS token airdrop. Assuming this price, $GRASS will be valued at a price of $0.35 with $350 million FDV. If we try to backtest GigaBuds floor price history, the $GRASS valuation will sit at $100-$350 million.

It's worth noting that Binance officials have tweeted "touch grass" several times in the past. While this phrase may not necessarily indicate their listing intentions, it has become a popular meme within the Grass community, helping to spread awareness and cultivate the project's ethos.

Conclusion and Outlook
In conclusion, Grass has achieved an incredible milestone by onboarding over 2 million users to build a decentralized web scraping network. More significantly, through worldwide contributions, Grass is beginning to exert tangible influence on the open-source dataset sector.
The emergence of data protocols like Grass may disrupt the current industry structure and make significant implications on the AI landscape. It’s reasonable to expect that democratized data access could lead to a surge in AI startups and research projects. The influx of new players might accelerate the pace of innovation, potentially leading to more frequent breakthroughs. In the meantime, the data crowdsourcing model may redirect some of the economic value currently concentrated in tech giants to a wide range of data contributors, altering the public involvement pattern and company valuations.
Looking ahead, Grass harbors ambitious goals in the field of AI data. In the near term, Grass is focusing on a broader mobile rollout, aiming to expand the network to all Android phones within the next couple of months, thus further increasing the user base and network capacity. Next, Grass plans to introduce data labeling features, adding another layer of value to their offerings. Grass is also developing an enterprise-grade implementation of their real-time context retrieval capabilities, which could be a game-changer for real-time AI applications.
It's worth noting that Grass is developing its own Layer 2 data rollup solution to handle the high volume of transactions and implement robust data provenance verification and value-add services. Ultimately, Grass envisions creating a decentralized knowledge graph of the entire internet by scaling 100 million nodes in its ecosystem, positioning itself as a crucial infrastructure layer for the future of the AI data market.

Author Thoughts
Grass represents an innovative initiative that leverages cryptocurrency to facilitate crowdsourced open web data scraping. But to answer whether it may succeed, let's break it down into key questions.
Demand for Data in AI Development
In recent years, AI has made remarkable strides, shaping the trajectory of growing demand for data. The global AI data management market, currently valued at $26.32 billion in 2023, is projected to reach an impressive $185.35 billion by 2032, according to a recent study by Polaris Market Research. The growth is exemplified by companies like Scale AI, a leading data services provider, which reported a staggering $760 million in annual recurring revenue (ARR) for 2023 — a 162% increase from the previous year.

As AI models continue to evolve, their appetite for data grows exponentially, making data an increasingly valuable commodity. In such a landscape, Grass emerges as an innovative alternative, poised to meet the surging demand for data in the AI market. By offering a fresh approach to data acquisition and management, Grass seems to have potential to grab a decent share in the rapidly expanding data field.
Network Effects
Like the other DePIN projects, the growth and success of Grass hinges on the power of network effects. The "scrape to earn" feature serves as a compelling catalyst for onboarding new Grass nodes. As the network grows, it can harness economies of scale, enhancing the project's long-term sustainability. However, network growth presents its own set of challenges. As the number of nodes increases, the token ecosystem faces dual pressures: heightened sell-side activity and a dilution of incentives. These factors could potentially dampen user enthusiasm and impede the formation of positive feedback loops. How to address incremental sale pressure and maintain node yields during network expansion would be a key to sustaining network health and growth momentum.
Data Process
Data processing for AI training is a crucial step that significantly impacts the quality and effectiveness of the resulting AI models. The process typically involves several stages to clean, organize, and transform raw data into a format suitable for machine learning algorithms. It's a good signal that Grass begins to process collected data and offer comprehensive value-add data services.
Demand Side and Pricing
Grass claims its bandwidth clients “include Fortune 500s, as well as institutions like Colleges and Universities”. The network's primary demand comes from AI developers and researchers who are priced out of or restricted from accessing datasets monopolized by tech giants. It's crucial for Grass to attract and extend these customers by offering high-quality data at competitive prices compared to traditional providers. Furthermore, the demand side is vital for maintaining a sustainable incentive structure, as it likely absorbs the tokens generated through data mining activities.
Data Privacy and Legality
The intersection of data privacy and web scraping legality is a complex and evolving area that Grass and similar projects must navigate carefully. Web scraping can inadvertently collect personal information, even from public websites. It raises concerns about compliance with data protection regulations like GDPR in Europe or CCPA in California. In addition, web scraping laws vary markedly across countries. Grass's global nature could expose it to legal challenges in multiple jurisdictions.
Ending
Grass's approach to these issues will be vital for its long-term viability and acceptance in the AI ecosystem. It may need to balance its decentralized ethos with centralized oversight on legal and ethical matters to navigate these complex issues effectively. While it's uncertain how Grass will address the aforementioned challenges, those considering a trade or investment in the project should monitor its progress closely.
Awesome info mate, 👏🏻🤝🏼